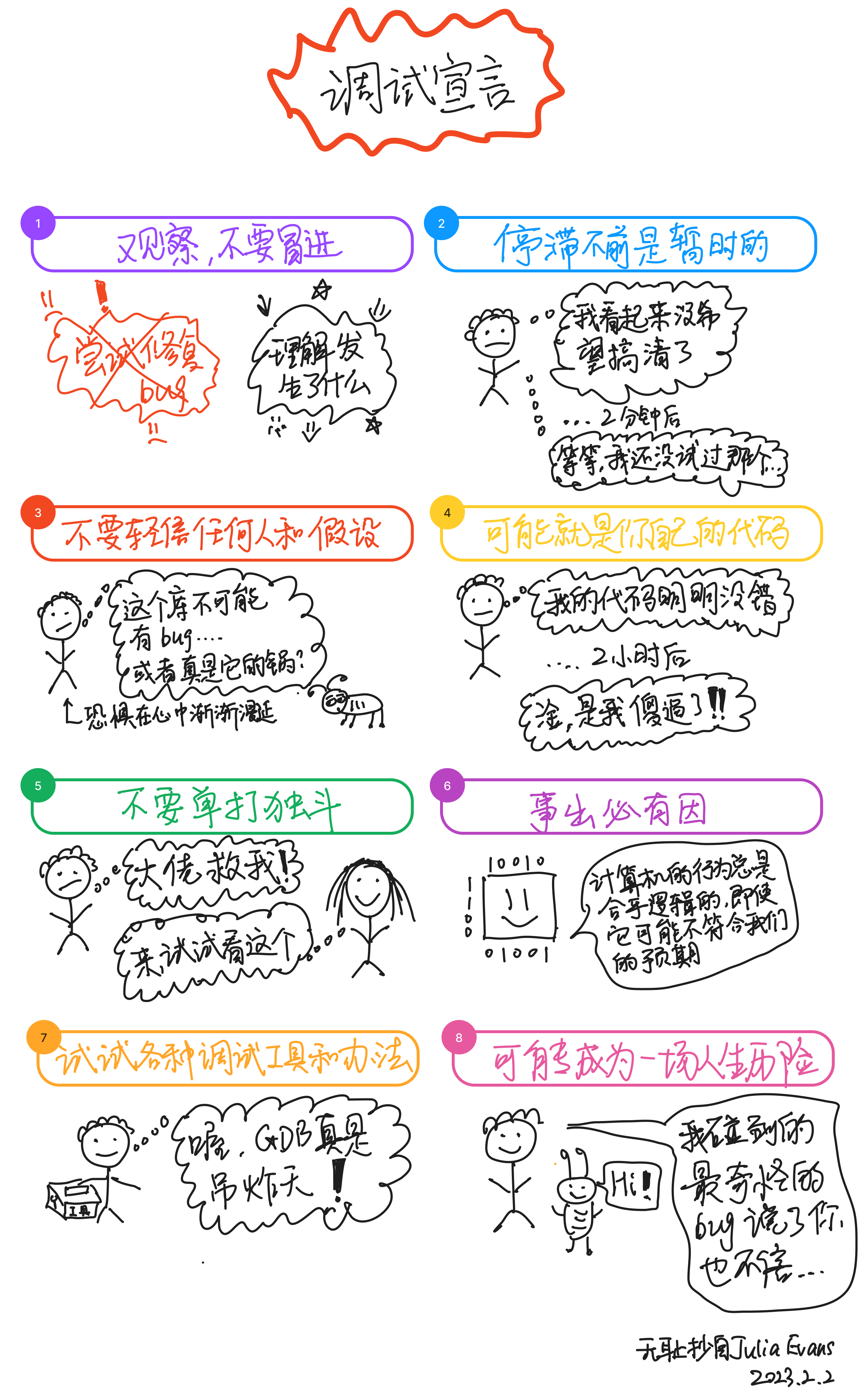
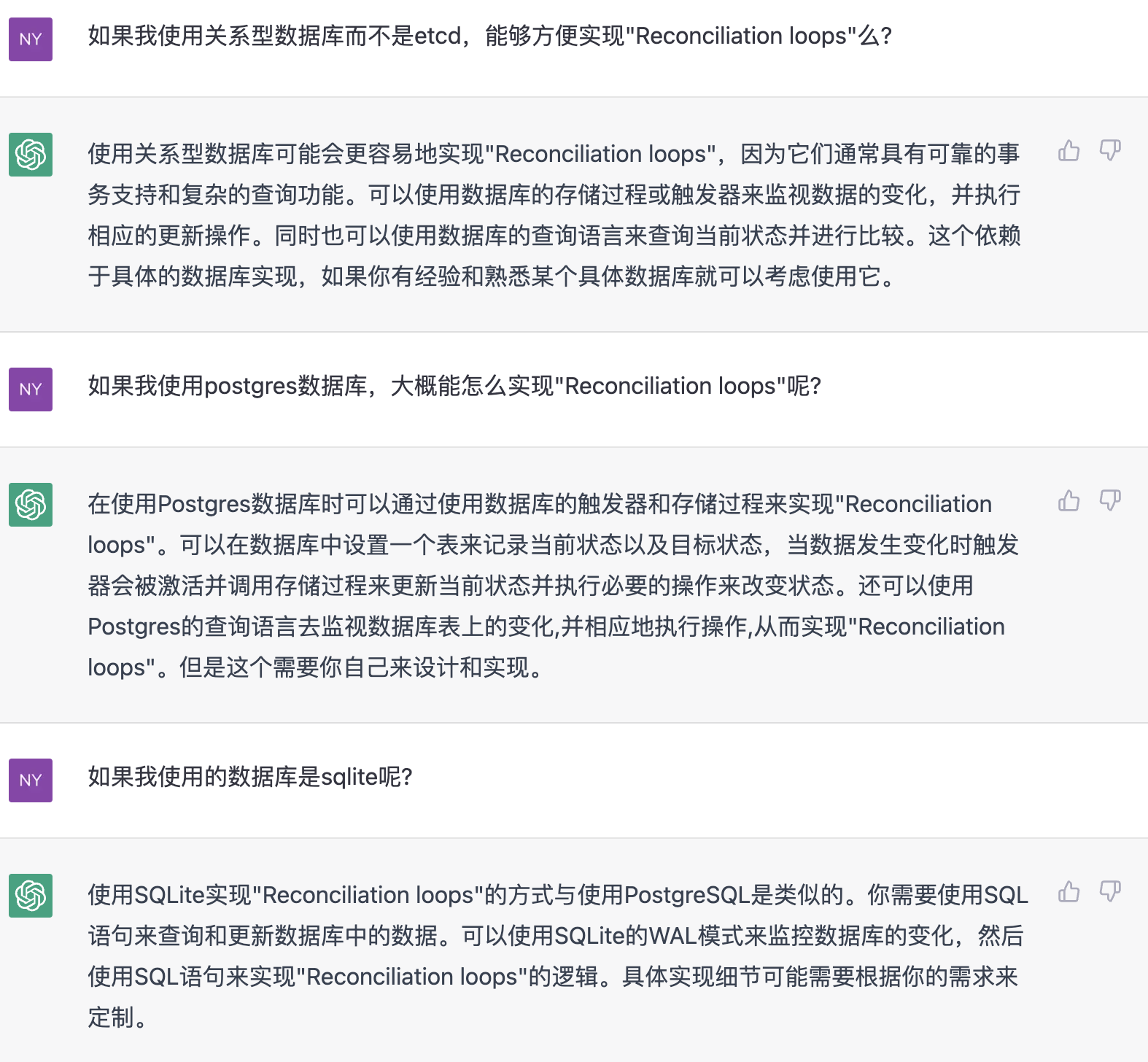
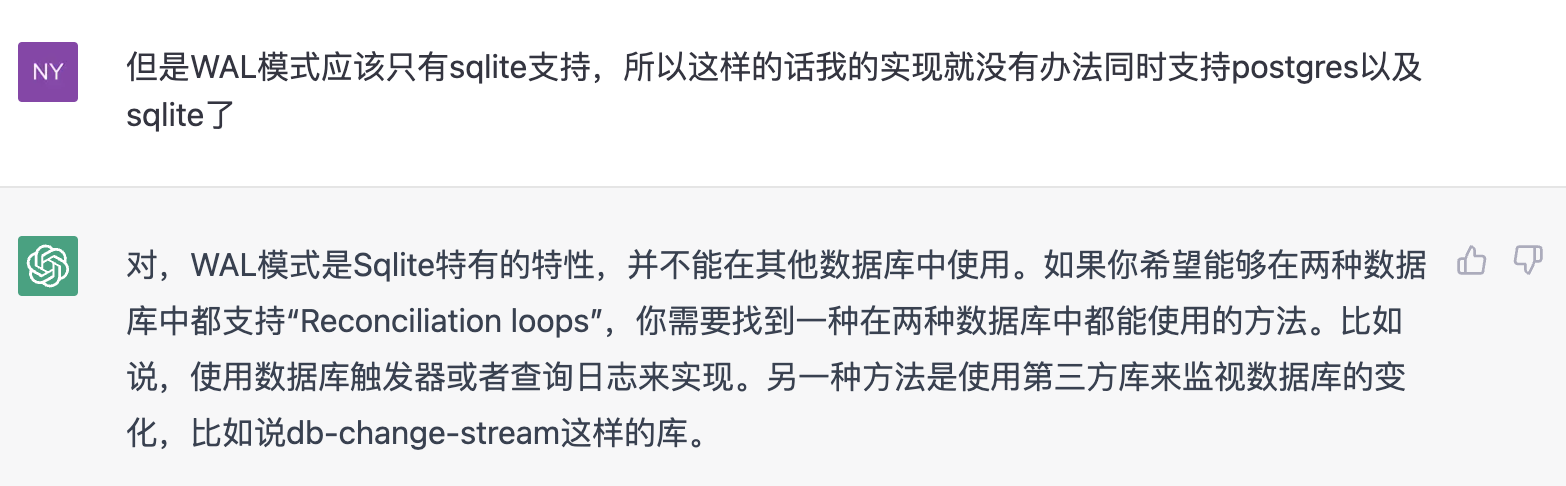
过去这些年,我陆陆续续阅读并收集了一些关于数据库和可观测性数据的资料。虽然期间也在内部做过一些英文资料的分享,但一直缺乏整理和公开发布的动力和时间。现在想想,即使这些内容还不够系统、也没有太多我自己的观点,还是值得陆续发布出来,也算是这些年积累下来的思考和学习的痕迹。
简介
Sneller是一个很有特点的数据系统,它用来处理日志数据:
- schemaless的存储和计算,非常适合处理半结构化的JSON数据
- 计算引擎使用golang实现,但是大量使用了AVX-512汇编语言来实现算子中的性能要求特别高的部分,以至于这部份代码非常难读懂😆
- 存储使用了一种二进制JSON的格式,同时用了一种很特别的compression tiling的方法,把JSON中的字段进行了分桶存储,这样读取的时候可以做到类似列式访问的方式从磁盘读取更少的数据
Sneller
- World’s fastest log analysis: λ + SQL + JSON + S3
- SQL for JSON at scale: fast, simple, schemaless
Intro
Sneller is a high-performance SQL engine built to analyze petabyte-scale un-structured logs and other event data.
Sneller vs. other SQL solutions:
- Sneller is designed to use cloud object storage as its only backing store.
- Sneller’s SQL VM is implemented in AVX-512 assembly. Medium-sized compute clusters provide throughput in excess of terabytes per second.
- Sneller is completely schemaless. No more ETL-ing your data! Heterogeneous JSON data can be ingested directly.
- Sneller uses a hybrid approach between columnar and row-oriented data layouts to provide lightweight ingest, low storage footprint, and super fast scanning speeds.
Wy We Built A Schemaless SQL Engine
- JSON has become one of the most common data interchange formats used in software engineering
- bridges the gap between distributed columnar data-stores and document stores
- it provides a SQL-like interface for un-structured data (like billions of JSON records)
- with the flexibility of a document store database and the performance of a modern distributed columnar database
- it provides a SQL-like interface for un-structured data (like billions of JSON records)
- Unlike typical columnar databases, the Sneller SQL engine is agnostic to the layout of the data ingested into records
- every record in our on-disk format is fully self-describing
- Consequently, we can ingest and query JSON documents without any configuration dictating the expected layout of the input data
- every record in our on-disk format is fully self-describing
Other benefits of schemaless
- On top of the improved flexibility, there are other operational benefits to avoiding a schema in your observability pipeline.
- Your logs or metrics won’t suddenly stop ingesting because someone accidentally deployed code that produces de-normalized data
- and you won’t have to worry about scheduling downtime because you need to run an expensive ALTER TABLE operation as part of a migration.
- Migrations become particularly troublesome when the tables in question have grown to petabytes in size; it often isn’t practical to re-write that much data
Compute
SQL VM
- a bytecode-based virtual machine written almost entirely in AVX-512 assembly
- our interpreter operates on flexibly-typed rows rather than on strictly-typed columnar data
design goal
- One of the UX goals we have for Sneller is to provide consistent, predictable performance across a wide range of possible queries
- Sneller Cloud’s pricing is based on the number of bytes scanned and not the total number of CPU cycles consumed by the query
- we’d like the ratio between the number of CPU cycles consumed and the number of bytes scanned to remain roughly constant
- if a user adds a regular expression search to a WHERE clause in a query, we’d like that to consume only marginally more CPU time
example
SELECT SUM(y)
FROM my_table
WHERE x < 3
ITERATE my_table -> FILTER (x < 3) -> AGGREGATE SUM(y) -> output
- Amazon Ion binary format [3]
- Each row of data is an ion structure composed of zero or more fields which themselves may be structures or lists (much like JSON records)
- Evaluating x < 3 means locating the x field in each structure, unboxing it as a number, and then comparing it against the constant 3
- We don’t typically know in advance that x will be a number, or even that x will be present at all, but we’ll see that the interpreter deals with data polymorphism just fine
expression evaluation
- Expression AST
func NewFilter(e expr.Node, rest QuerySink) (*Filter, error)
// NewFilter constructs a Filter from a boolean expression. The returned Filter
// will write rows for which e evaluates to TRUE to rest.
- SSA IR (single static assignment intermediate representation)
- Steps
- convert the input AST into a Single Static Assignment-based intermediate representation
- convert SSA IR into a representation that is actually executable by our bytecode VM
- SSA instructions generally map 1-to-1 to bytecode VM instructions
- The bytecode VM just executes a linear sequence of instructions
- so our first order of business is computing a valid execution ordering of the SSA instructions
- A post-order traversal of the SSA program beginning at the return instruction will always produce a valid instruction ordering
AVX 512
- the most important feature of AVX-512 as compared to AVX2 is the presence of “mask” (or “predicate”) registers.
- Most AVX-512 instructions accept a mask register (k0 through k7) operand that causes the lanes corresponding to the zero bits of the mask to remain untouched by the instruction in question
vpaddd %zmm12,%zmm7,%zmm7{%k5}- The instruction above adds the sixteen 32-bit integers in zmm12 to the corresponding 32-bit integers in zmm7 and writes the results into zmm7, but only for the lanes where k5 is set. In other words, this instruction does not modify any lanes in zmm7 where k5 is unset.
AVX 512
if (x < 3) {
x += 2;
} else {
x -= 1;
}
;; assume we have broadcast
;; 1 into %zmm1,
;; 2 into %zmm2,
;; 3 into %zmm3
vpcmpltd %zmm3, %zmm0, %k1 ;; k1 = zmm0 < zmm3, per lane
knotw %k1, %k2 ;; k2 = ~k1
vpaddd %zmm0, %zmm2, %zmm0{%k1} ;; zmm0 += 2 iff k1
vpsubd %zmm1, %zmm0, %zmm0{%k2} ;; zmm0 -= 1 iff k2
- Implementation targets
- Intel AVX-512
- ARM SVE/SVE2 and the RISC-V Vector Extension
Trampolines
Once we have an executable sequence of bytecode operations, we need a way of entering the VM from portable Go code.
- Each of the physical operators implements a “trampoline” function (written in assembly) that
- populates the right VM registers with the initial state for a group of up to sixteen rows
- invokes the bytecode by jumping into the first virtual instruction
- and then takes the return value from the VM and does something sensible with it
- Trampoline routines can typically accept an arbitrarily large number of input rows.
- We usually aim to process several hundred rows of data per call.
- Importantly, this means that we spend basically zero time in actual portable Go code once we have compiled the bytecode;
- the “inner loop” of the VM is implemented entirely in assembly.
- This is a critical piece of the design, because it means the Go language does not meaningfully constrain the performance of the VM as compared to “faster” alternatives like C/C++ or Rust.
unpivot_accelerators_amd64.s
- we have more than 250 bytecode operations, spanning everything from hash trie lookup to string matching to great-circle distance calculation
Storage
Columnar Compression Without Columns
- uses object storage as its primary storage back-end is frequently going to have to move data across a network
- and network bandwidth is often a limiting factor for overall system performance
- renting a 200Gbps-capable c6in.32xlarge instance
- download data from S3 at a maximum rate of 200 Gbps (23.28 GB/s)
- c6in.32xlarge machine has 128 CPU cores, and we can decompress zstd data at over 1 GB/s/core (in decompressed bytes) (128GB/s)
- a compression ratio of at least 5.49 (128 / 23.28)
Columnar Compression Without Columns
- Since Sneller’s query engine is fundamentally row-oriented, and since Sneller supports arbitrary heterogeneous rows, we cannot employ exactly the same tricks as a “pure” columnar storage format
- Sneller allows users to provide entirely disjoint sets of fields in adjacent rows.
- One thousand rows with ten fields each that are unique to the row would imply that there are ten thousand “columns” just for those one thousand rows!
- Sneller allows users to provide entirely disjoint sets of fields in adjacent rows.
- our SQL virtual machine can process more than 4GB/s/core of raw ion data
- whereas zstd decompression typically runs at only about 1GB/s/core
Columnar Compression Without Columns – “Compression tiling”
In order to provide some of the performance benefits of compressed columnar storage, we use a technique we call “compression tiling”
Compression tiling
- amazon ion [3]
- Amazon Ion is a richly-typed, self-describing, hierarchical data serialization format offering interchangeable binary and text representations.
- The text format (a superset of JSON) is easy to read and author, supporting rapid prototyping.
- The binary representation is efficient to store, transmit, and skip-scan parse.
Compression tiling
zionformat (zipped ion)- 16 buckets
- Each block of data (a group of rows) has its top-level fields hashed into one of sixteen buckets
- each of the sixteen buckets of data is compressed separately
zionbucket- Each zion “bucket” encodes both the field label (as an ion symbol) and the field value for each assigned field in each record
- Prepended to the sixteen compressed buckets of data is a compressed “shape” bitstream that describes how to traverse the buckets to reconstruct the original ion records.
- use the
zstdgeneral-purpose compression algorithm for compressing- all the buckets
- the “shape” bitstream
Compression tiling – query against zion format
- we can elide reconstruction of all the fields of each record that are not semantically important for the query
- which means that we can achieve up to a 16x reduction in the amount of time we spend decompressing data
zion example
text: { my_string: "hello", my_number: 3, my_bool: false }
binary: db8a8568656c6c6f8b21038c10
- ion symbols
0x0a==>my_string0x0b==>my_number0x0c==>my_bool- assume those symbols end up being hashed to buckets 5, 3, and 1
zion example
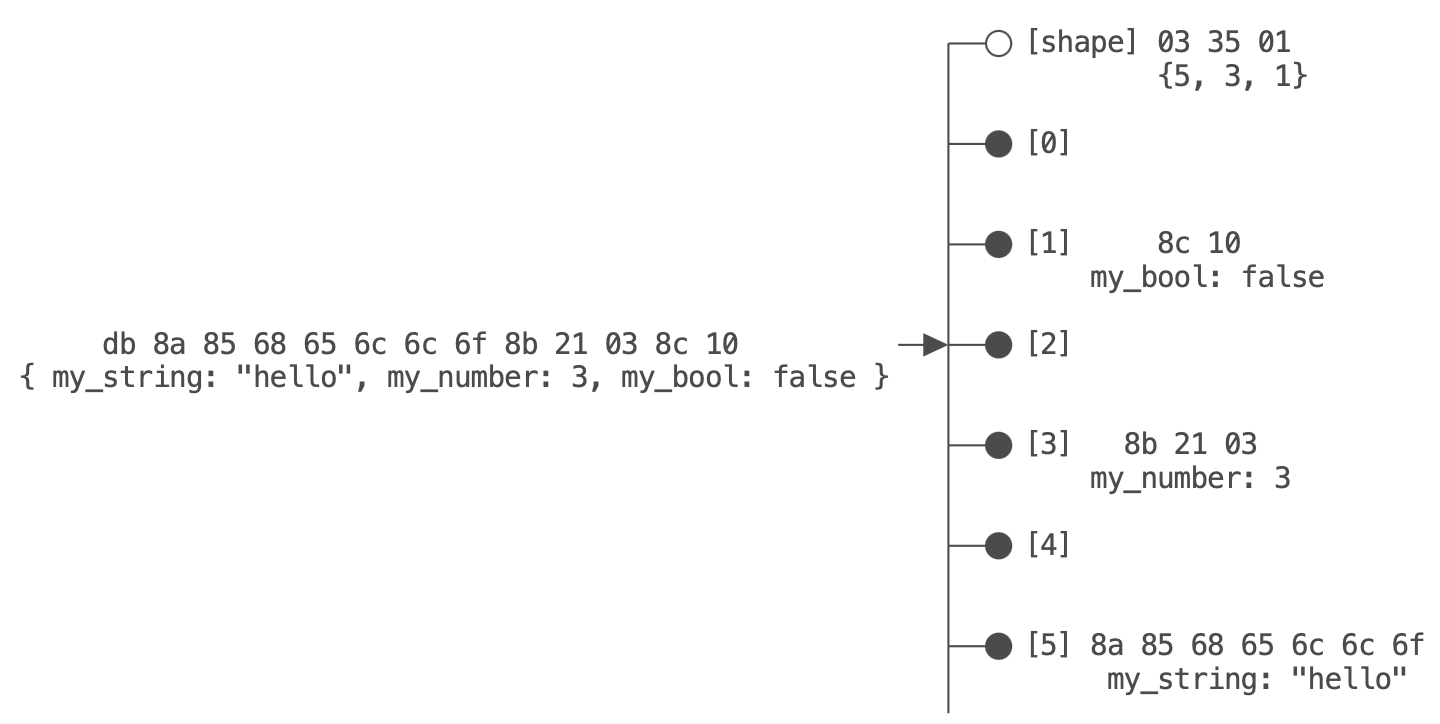
- shape bitstream
- we’d write
033501- The first byte 0x03 indicates that we encoded a row with three fields
- The next two bytes encode the buckets as individual nibbles, lsb-first
- always round the encoded size of an individual “shape” into an even number of bytes
- we’d write
- repeat the process above for every new row of ion data for the block
- also include the ion symbol table in the shape bitstream
- compress the shape bitstream and the buckets and concatenate them to form a complete compressed zion block
zion format
In practice, zion-compressed ion data with zstd-compressed buckets tends to be about 10% smaller than simply wrapping the ion data with zstd compression naïvely
Decoding zion
- Decoding a zion block is just a matter of running all the encoding steps above in reverse
- After decompressing the shape bitstream and symbol table, we can map any requested fields (e.g. my_string) to symbol IDs, and we can hash those to determine which bucket(s) need to be decompressed
- we iterate the shape bitstream one item at a time and emit an ion structure composed of the field/value pairs encoded in each of the bucket(s) that we decompressed, taking care to omit any fields that we aren’t interested in reconstructing
- If we only need to produce one field, then we only have to decompress one bucket, and consequently we do (approximately) 1/16th of the decompression work
Decoding Performance
Our SQL engine is quite sensitive to the performance of the “reconstruction” process for ion data from zion blocks
- The implementation of
zion.Decoder.Decodeuses one of a handful of assembly routines - We’ve managed to make this reassembly process quite fast (many GB/s/core) in practice.
Partitioning
Partitioning can be configured for a table to improve data locality, provide data isolation, and reduce the number of bytes that need to be scanned to satisfy a query
{
"input": [
{
"pattern": "s3://example-bucket/logs/{region}/*.json.zst"
}
],
"partitions": [
{
"field": "region"
}
]
}
logs/eu-west-1/access-log.json.zst
logs/eu-west-1/error-log.json.zst
logs/us-east-1/access-log.json.zst
logs/us-east-1/error-log.json.zst
logs/us-west-2/access-log.json.zst
logs/us-west-2/error-log.json.zst
SELECT COUNT(*) FROM logs WHERE region = 'us-west-2'
Partitioning on dates
{
"input": [
{ "pattern": "s3://example-bucket/logs/{yyyy}/{mm}/{dd}/*.json.zst" }
],
"partitions": [
{ "field": "date", "type": "date", "value": "$yyyy-$mm-$dd" }
]
}
Sneller SQL
- Sneller SQL only supports part of the “DQL” portion of standard SQL (i.e. SELECT-FROM-WHERE statements, etc.).
- Sneller does not currently use SQL to perform database insert/update operations
Sneller SQL
- Sneller SQL extends the concept of SQL “rows” and “columns” to “records” and “values”
- In other words, each “row” of data is a record of values, and records themselves are also values.
- A “table” is an un-ordered collection of records.
Instead of projecting “columns,” a Sneller SQL query projects record fields.
SELECT 1 AS x, 2 AS y, (SELECT 'z' AS z, NULL AS bar) AS sub
evaluates to:
{"x": 1, "y": 2, "sub": {"z": "z", "bar": null}}
Sneller SQL
Sneller SQL can handle tables that have records with wildly different schemas, as it does not assume that the result of a particular field selection must produce a particular datatype
Execution model
Since Sneller is designed to run as a “hosted” multi-tenant product, the query engine and query planner are designed so that queries will execute
- within a (generous) fixed memory limit
- and a linear amount of time with respect to the size of the input
Core types
- Null
- Sneller SQL departs from ordinary SQL in that the value NULL compares equal to itself
- We chose to depart from the SQL standard here so that it would be possible to compare lists and structures with NULL fields using the = operator.
Core types
- Missing
MISSINGis the notation for the absence of a value.- Since Sneller SQL has functions and operator that only operate on certain data-types, some operations may not return a meaningful result.
- For example, the result of the expression 3 + ‘foo’ is MISSING, since we cannot add the integer 3 to the string ‘foo’
- Similarly, the result of a path expression foo.bar where the value foo is not a structure (or foo is a structure without any field called bar) is also MISSING
- When projecting columns for output, the Sneller SQL engine will omit labels for columns that produce MISSING. In other words, an expression that evaluates to {‘x’: ‘foo’, ‘y’: MISSING} is output as {‘x’: ‘foo’}
Subquery restrictions
Since the query engine implements sub-queries by buffering the intermediate query results, sub-queries are not allowed to have arbitrarily large result-sets.
The query planner will reject sub-queries that do not meet ONE of the following conditions:
- The query has a LIMIT clause with a value of less than 10,000.
- The query has a SELECT DISTINCT or GROUP BY clause.
- The query is an aggregation with no corresponding GROUP BY clause (and thus has a result-set size of 1).
- Additionally, the query execution engine will fail queries that produce too many intermediate results. (Currently this limit is 10,000 items.)
Ordering restriction
The ORDER BY clause may not operate on an unlimited number of rows, as it would require that the query engine buffer an unlimited number of rows in order to sort them.
The query engine will reject an ORDER BY clause that occurs without at least one of the following:
- A LIMIT clause of 10000 elements or fewer
- A GROUP BY clause
Querying multiple tables at once (‘++’ operator)
The operator ++ (double plus) allows to concatenate multiple sources into one. The operator is shorthand for UNION ALL; it allows to skip the common filter expression, selected columns, etc.
For example the following query will return results from three tables:
SELECT COUNT(*) FROM t1 ++ t2 ++ t3 WHERE location = 'Helsinki'
the company
- Frank Wessels, Founder & CEO
- Prior to founding Sneller, Frank was CTO at open source object storage startup MinIO
- pricing
- simple pricing: $50 per PB scanned, 100x less expensive
- sneller.io ==> sneller.ai
References
[1] https://github.com/SnellerInc/sneller
[2] zion format, https://sneller.ai/blog/zion-format/
[3] Amazon Ion binary format, https://amazon-ion.github.io/ion-docs/docs/binary.html
[4] Binary encoding, https://amazon-ion.github.io/ion-docs/docs/binary.html